Vibecoding an Open-Source SOC Platform: What Held Up and What Didn't
SOC Hub is now open source. The latest round was built mostly by describing features in plain English to an AI agent — here's what that actually looked like, including the parts where the vibe broke and judgment had to take over.
SOC Hub is open source now. The whole thing — multi-tenant case management, a local-LLM investigation copilot, IR playbooks, an investigation graph, per-tenant SAML SSO — is up on GitHub for anyone to read, run, or pull apart:
I want to talk about how the latest round got built, because it’s the part people keep asking about. Most of it I built by talking. I described features in plain English to an AI coding agent, it wrote the backend routes, the migrations, the React components, wired them up, and deployed them. “Vibecoding,” if you want the meme word for it.
That framing makes it sound effortless, and the honest version is more interesting than that. The vibe got me about 90% of the way, fast. The last 10% was all judgment — and the last 10% is where security software lives or dies.
What the copilot actually does
The piece I’m proudest of is the investigation copilot, because it’s designed around a boundary I didn’t want to cross: it never writes anything without you clicking confirm.
It runs on a local model through Ollama — case data, artifacts, prompts, none of it leaves the environment. You can chat with it about a case, and when you ask it to do something — add an IOC, record a timeline note, change severity — it doesn’t just do it. It proposes a structured action with a preview, and you approve or cancel.
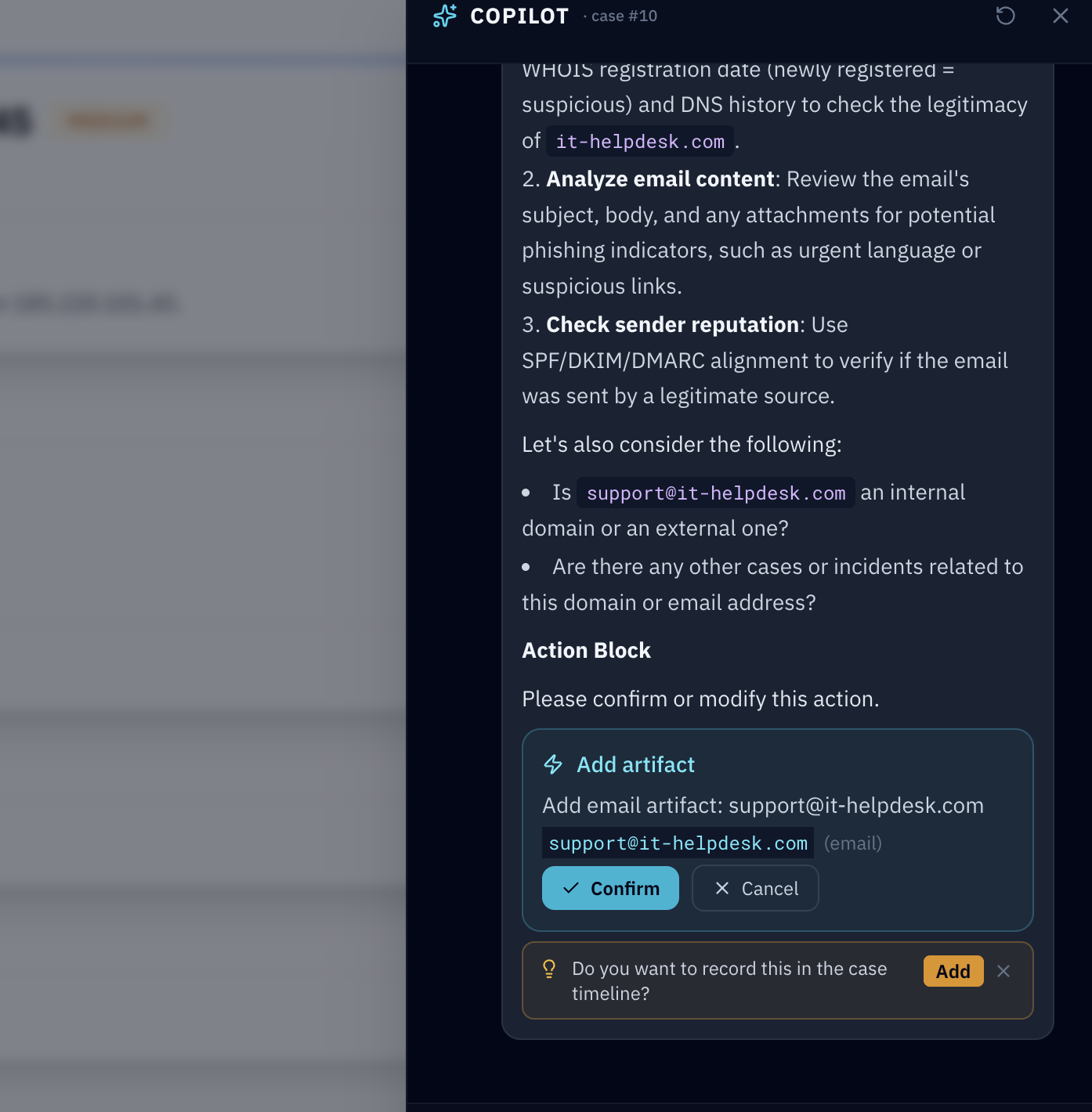
It also watches the conversation. Mention an IP or a domain mid-chat and it’ll offer to add it as an artifact. State a finding and it’ll offer to log it to the timeline. Suggestions, never silent writes.
Seeing the investigation as a graph
Investigations aren’t linear, they’re graphs — the same indicator shows up across cases that look unrelated until you put them next to each other. The investigation graph draws cases, artifacts, and IOCs as one map, with dashed bridges where the same value appears in more than one place.
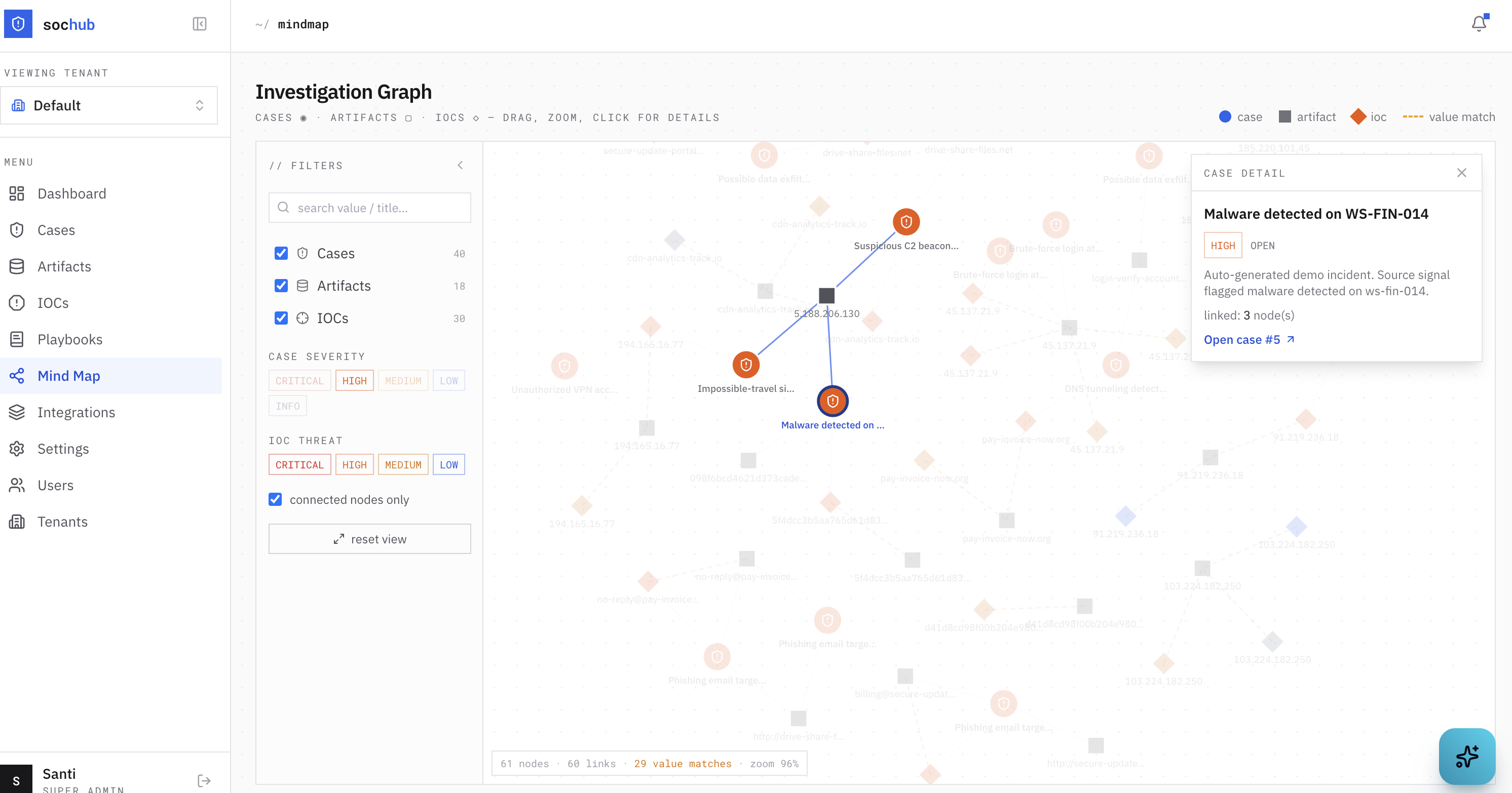
Filter by node type or severity, search, zoom, drag, click anything for a detail dossier. This is the layer where individual cases turn into “wait, these three are the same campaign.”
Playbooks that fill themselves in
There’s a marketplace of MITRE-mapped IR playbooks — phishing, ransomware, malware, unauthorized access, exfiltration, password spraying. Tenants import the ones they want and own editable copies.
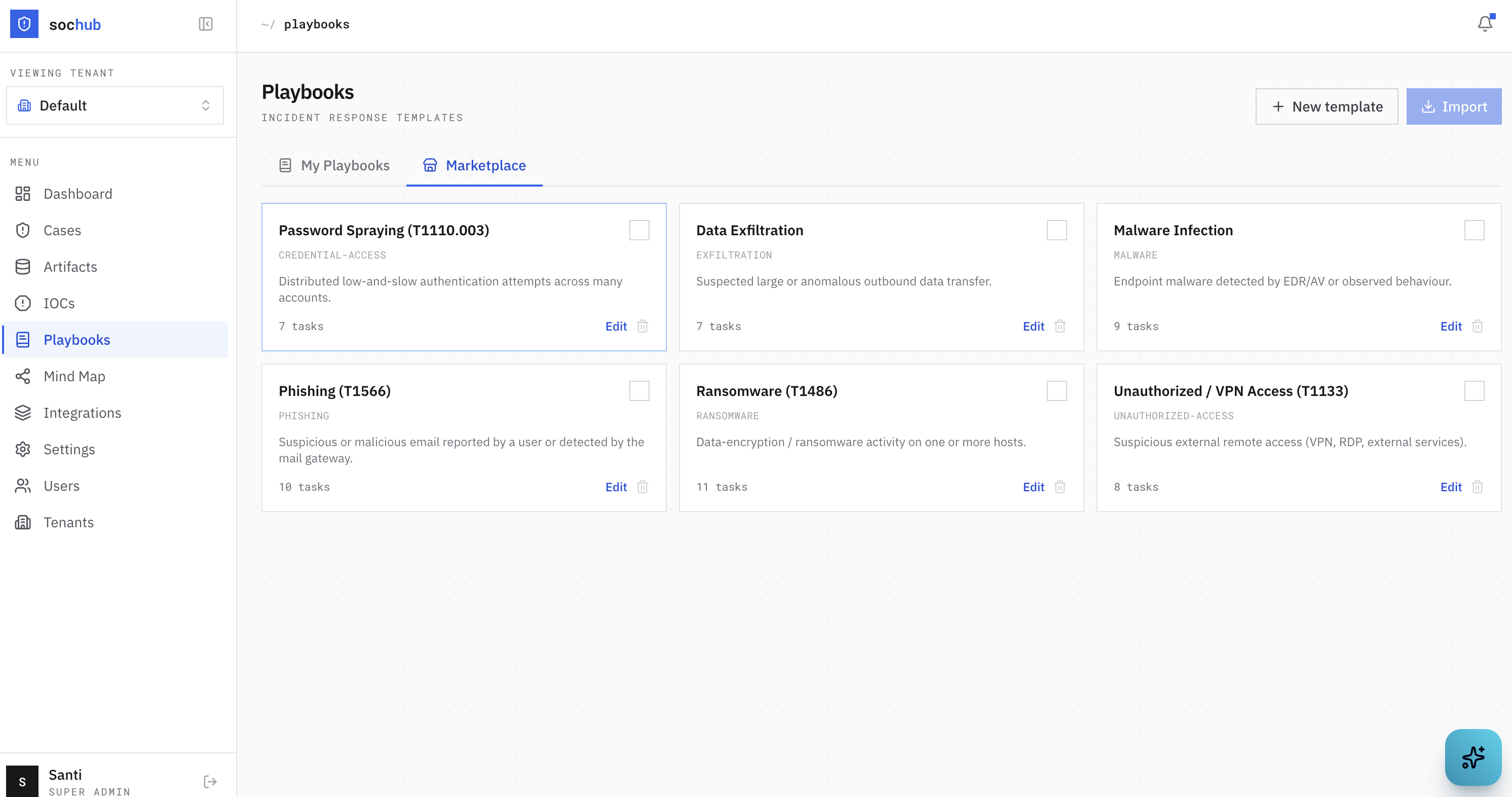
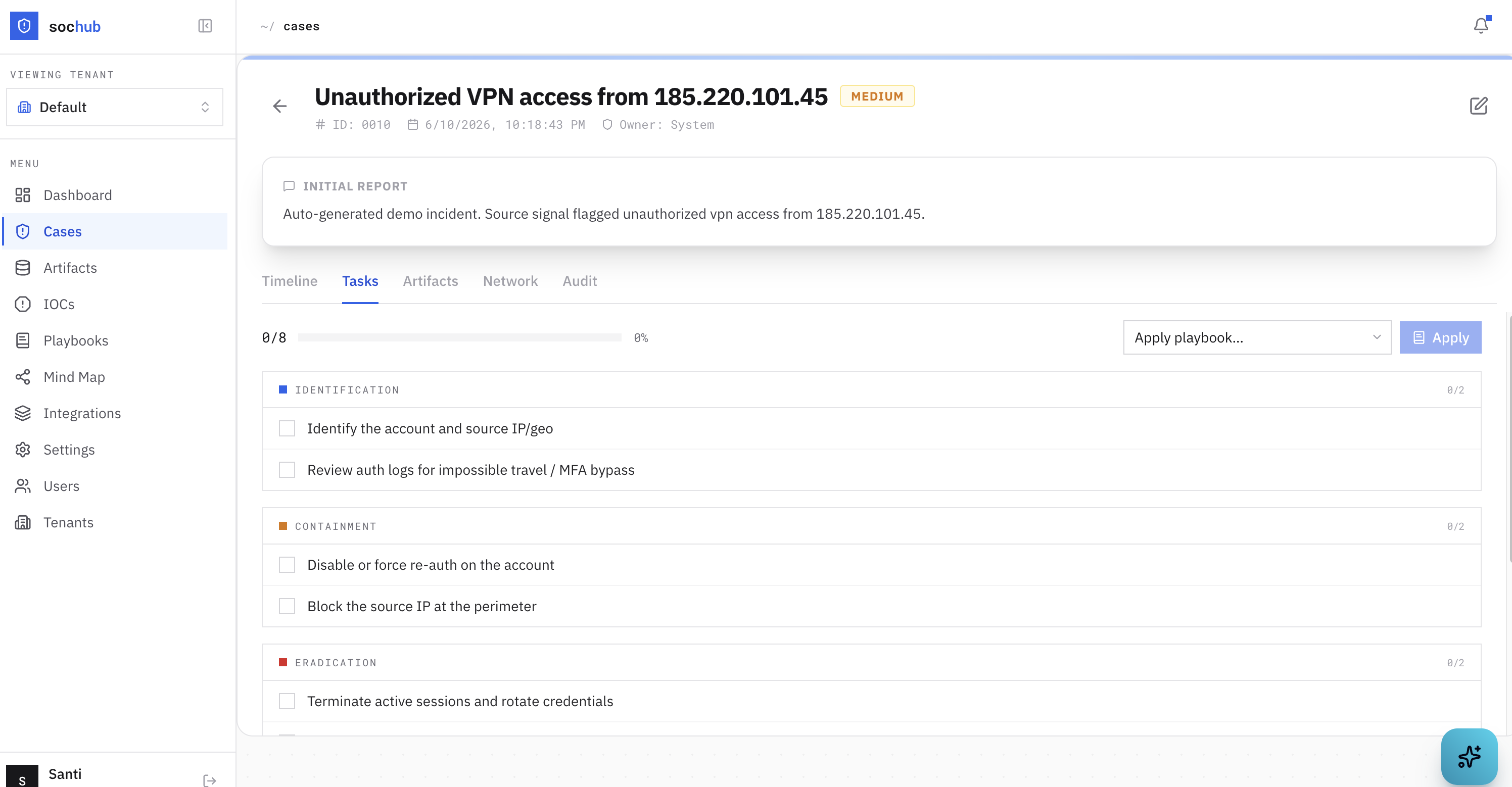
Apply one to a case and it fills in a phase-grouped task checklist — Identification, Containment, Eradication, Recovery, Lessons Learned — with a progress tracker, so the next analyst can see exactly where the last one left off.
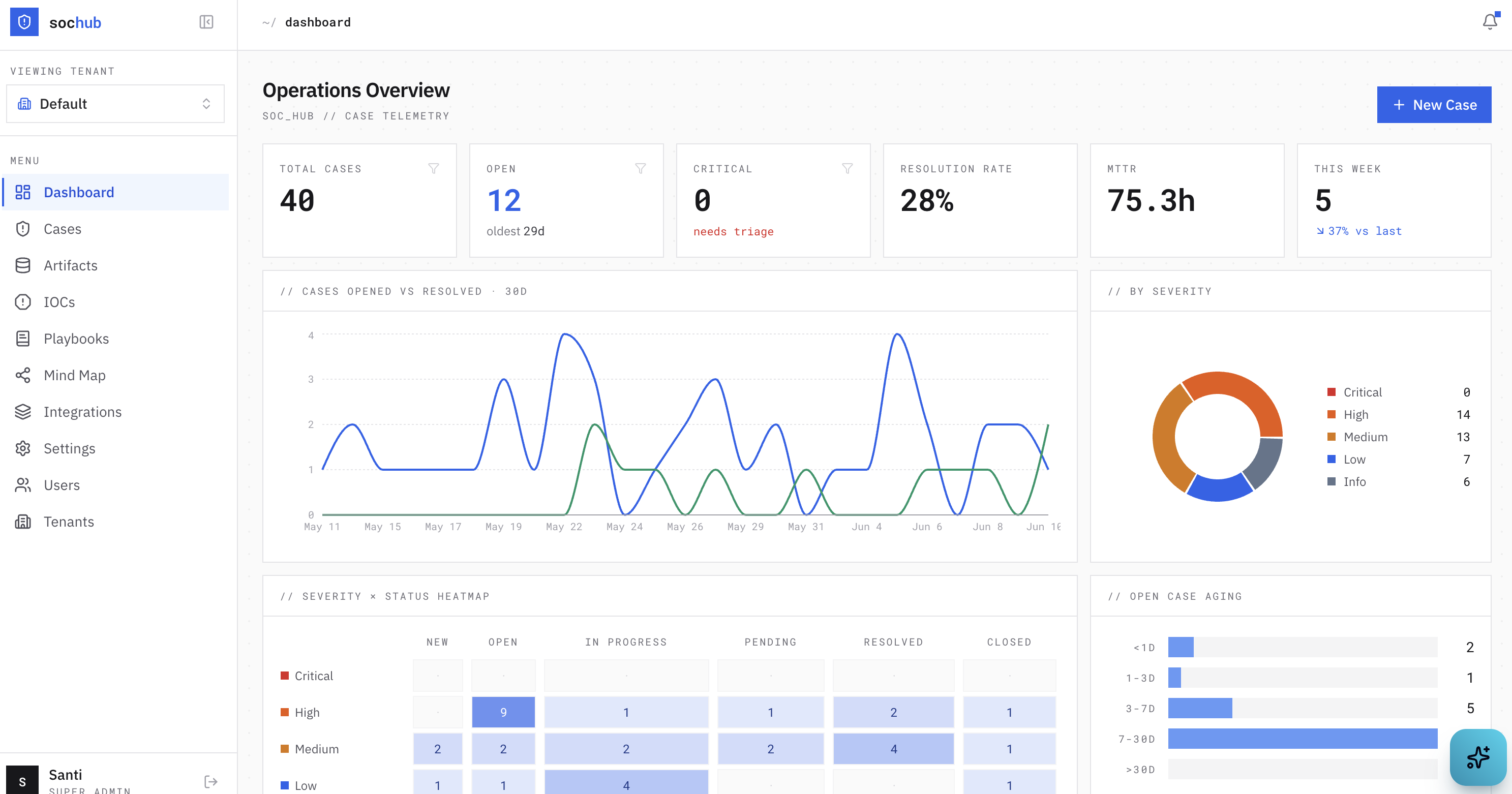
And the dashboard ties it together: open vs. resolved trends, a severity-by-status heatmap, open-case aging, MTTR.
Where the vibe broke
Here’s the part the demos skip.
The security review caught my own bugs — while I was pushing the repo public. An automated review flagged two real IDOR holes in code I’d just committed: the copilot chat scoped a session lookup to the tenant but not the user, so a tenant peer could have posted into someone else’s copilot session. And a Jira-sync endpoint dispatched a job with a caller-supplied case_id and no ownership check. Both are exactly the kind of cross-tenant leak that automated codegen produces confidently and a careless reviewer ships. The fix was easy. Noticing was the whole job.
The LLM kept lying about note content. Ask the copilot “add a comment: the user clicked the link on their phone” and the local model would cheerfully record a note that just said “Added activity log.” So I pulled note text out of the model’s hands entirely — the literal note content is parsed deterministically from your message, and placeholder garbage is rejected outright. The right answer wasn’t a better prompt; it was not asking the model to do the part it’s bad at.
A migration died on a fresh database. Everything worked incrementally, then I rebuilt from an empty DB and Postgres refused a migration — a new enum value being used in the same transaction it was added in. It had never surfaced because the migrations had only ever been applied one at a time. One config line fixed it, but you only find that by actually rebuilding from zero.
I switched container runtimes mid-build and lost the whole local database, re-bootstrapped from scratch, and made the model auto-pull on container start so the next person doesn’t hit the same wall. Then a separate pile of dependency advisories needed clearing. None of it was hard. All of it was the unglamorous reality that “the AI built it” and “it’s actually correct, safe, and reproducible” are two different finish lines.
The takeaway I keep landing on
AI builds fast. It does not have taste, and it does not have judgment, and in security that’s the entire game. The agent wrote thousands of lines I’d have happily merged — and a few I absolutely should not have, that looked identical to the good ones. The skill that mattered wasn’t typing the code. It was reading a diff and thinking “that’s a cross-tenant data leak” before it shipped.
That’s also exactly why I open-sourced it. If a tool is making decisions about your incidents, you should be able to read the code making them — not trust a vendor’s marketing over your own engineering judgment. And if it’s “AI-powered,” it shouldn’t require shipping your investigation data to someone else’s API to function. Local inference removes that tradeoff.
It’s all there to read, run, and tear apart:
If you run a SOC and any of this resonates — try it, break it, or tell me what you’d actually want a copilot like this to do for you. That feedback is worth more than any roadmap I’d write on my own.